Enhancing AI with Retrieval-Augmented Generation (RAG)
04.07.2024 - Tiziano PuppiArtificial Intelligence (AI) is becoming an integral part of our daily lives, revolutionizing various sectors and enhancing user experiences across the board. From virtual assistants to recommendation systems, AI is everywhere and is here to stay. One particularly promising area where AI could significantly improve user experience is in search functionality.
Traditional search engines rely on keyword-based queries to fetch relevant results. While this approach has served us well, it often falls short when users have complex queries or need specific information. Imagine a search experience where users can have natural, conversational interactions and ask detailed questions instead of typing keywords. This is where AI can truly transform the search landscape.
Large Language Models (LLMs)
Large Language Models (LLMs) like GPT-4 are at the forefront of this transformation. These models are incredibly powerful and capable of understanding and generating human-like text based on vast amounts of training data. However, their knowledge is confined to the information available during their training period. Without additional capabilities, such as real-time web browsing, their knowledge remains static and limited.
For businesses and organizations, this limitation poses a significant challenge. Internal knowledge and proprietary information specific to a company are not included in the LLM’s training data. Consequently, the LLM cannot provide insights or answers based on this crucial information, which restricts its utility in specialized contexts.
Introducing RAG
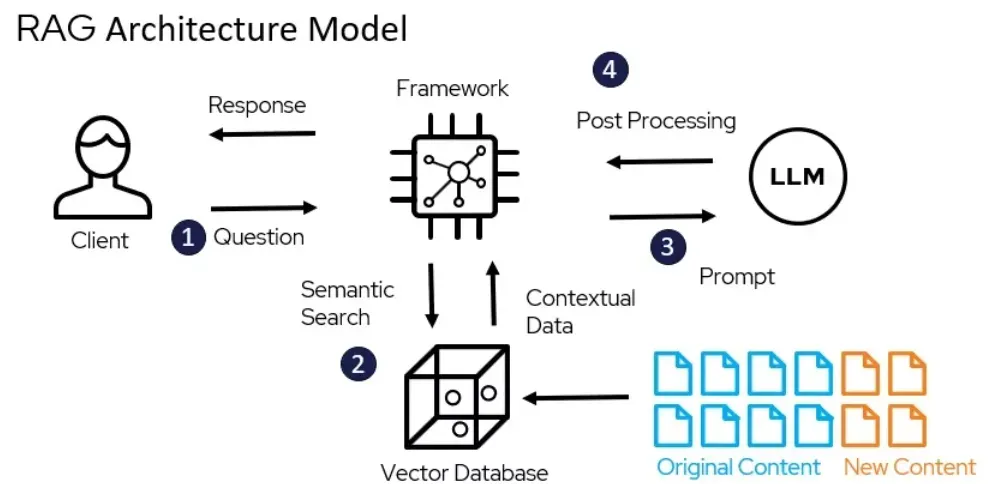
This is where Retrieval-Augmented Generation (RAG) comes into play. RAG is a technique designed to enhance the capabilities of LLMs by integrating a retrieval mechanism that fetches relevant external information in real-time. Essentially, RAG combines the generative power of LLMs with the precision of information retrieval systems, creating a more dynamic and contextually aware AI.
RAG works by incorporating a retrieval component that accesses external databases, documents, or other information sources when a query is made. Here’s a simplified explanation of the process:
-
User Query: The user inputs a question or query.
-
Initial Processing: The LLM processes the query to understand its context and intent.
-
Information Retrieval: The retrieval system searches for relevant documents or data sources that contain the information needed to answer the query.
-
Fusion of Information: The retrieved information is combined with the LLM’s generative capabilities to produce a comprehensive and contextually relevant response.
-
Response Delivery: The user receives a detailed and accurate answer that leverages both the LLM’s knowledge and the latest external information.
By augmenting LLMs with information retrieval, RAG bridges the gap between static training data and dynamic, ever-changing information needs. This hybrid approach ensures that users receive accurate and up-to-date answers, significantly improving the search experience.
Toy Example: Demonstrating RAG in Action
To make things more tangible, here is a small toy example that demonstrates how RAG works. In this example, we will take some rule sheets from popular board games. We will ingest the information contained in those rule sheets and populate a particular database with that information (or better, with the “embedding” of snippets of information that can be retrieved later).
- Ingesting Information: We take the rule sheets from board games like Monopoly, Ticket to Ride, Chess, and Scrabble. The information from these sheets is processed and stored in a database as embeddings – a way of representing textual data in a numerical format that the AI can easily work with.
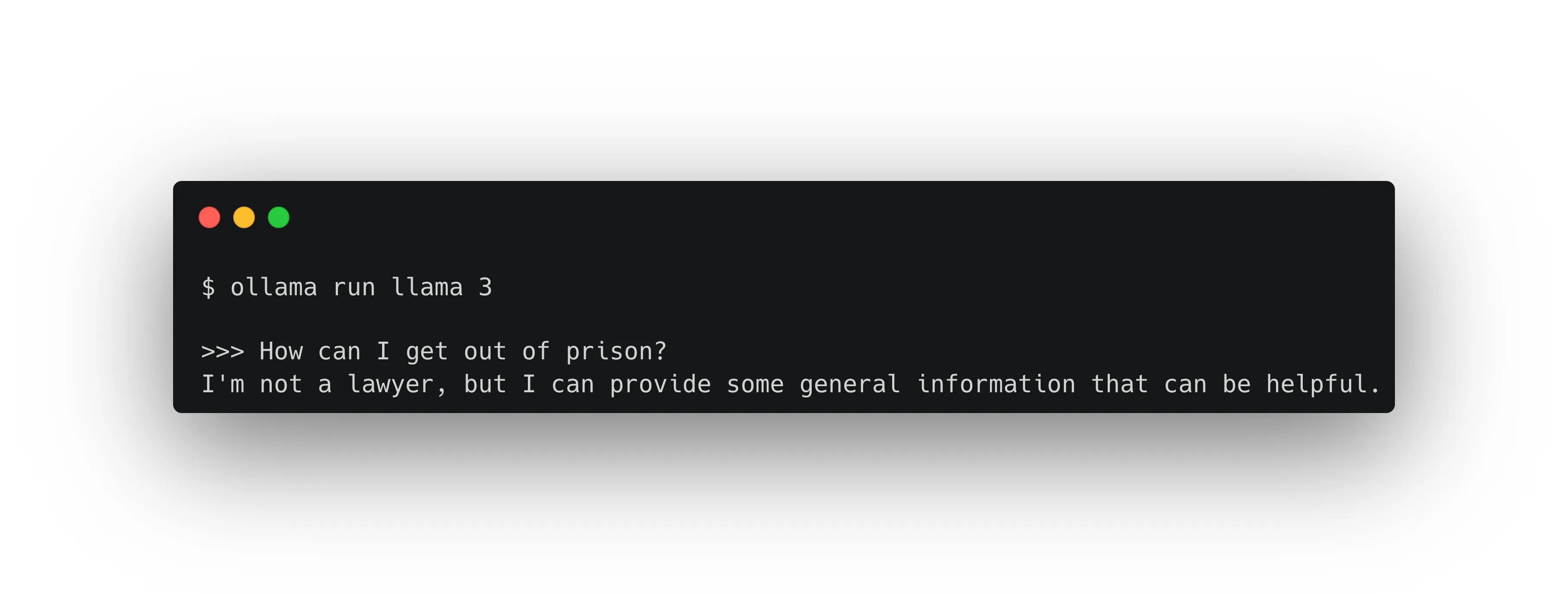
- Formulating a Question: Once the database is ready, we can formulate our question. For example, we could ask, “How do you get out of jail?”
- Generic LLM Response: Using only a generic LLM, this question is very tricky to answer. The response might be vague or incorrect because the model doesn’t have specific information about the game rules.
- RAG Response: Using RAG, the answer makes much more sense because it retrieves and uses the specific information from the ingested rule sheets. The system searches the database for relevant snippets about Monopoly’s jail rules and integrates this information into its response, providing an accurate and contextually appropriate answer.
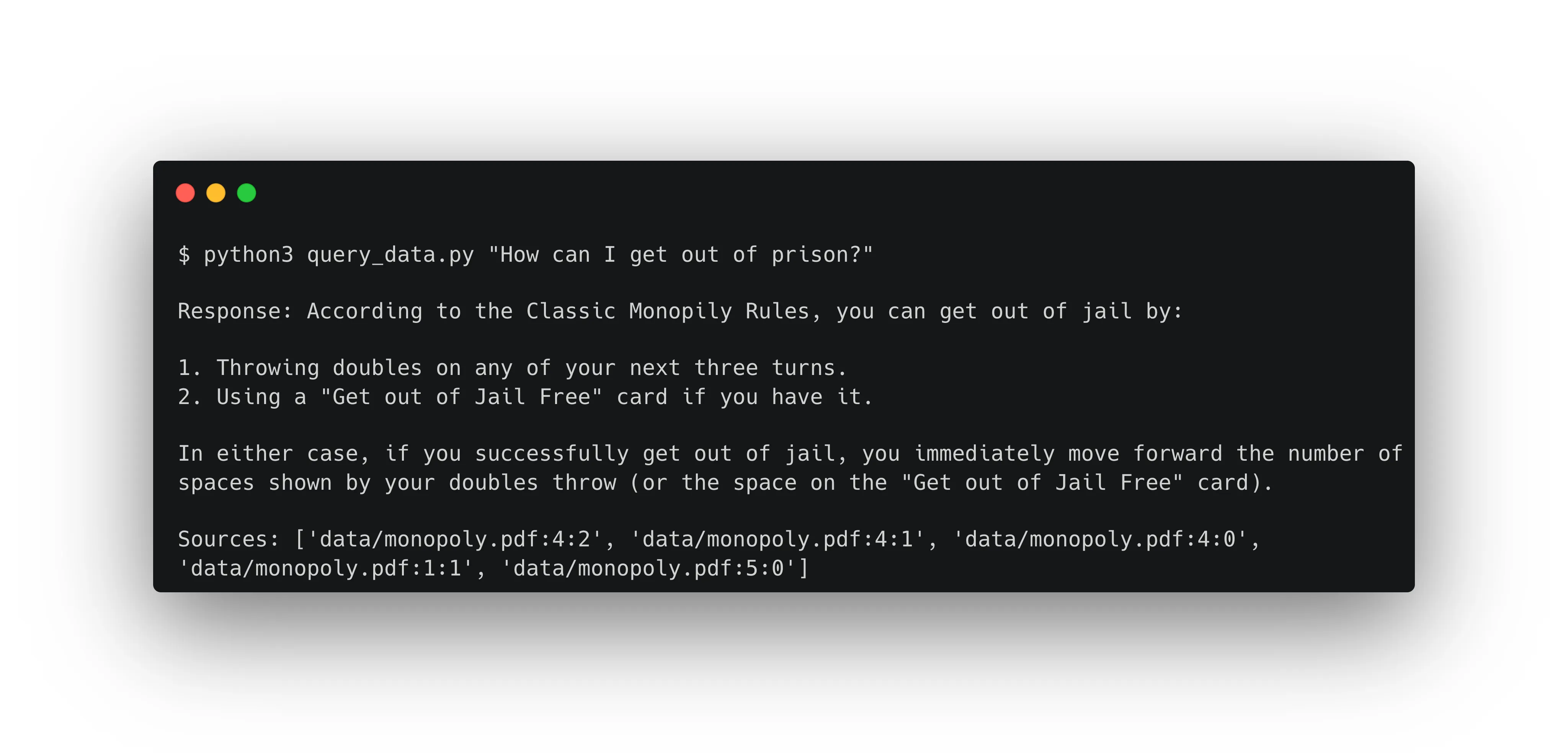
By incorporating specific, real-time information into its responses, RAG enhances the capabilities of LLMs, making them far more effective in specialized and dynamic contexts.
Technical Deep Dive (a more detailed explanation)
Ingestion Phase
In the ingestion phase, the text in the PDFs containing the board game rules is extracted. This text is then divided into overlapping chunks of a fixed size. Each chunk is passed through an AI model to generate an embedding.
An embedding is a numerical representation of text that captures its semantic meaning. It transforms text into a format that an AI model can understand and manipulate. Embeddings allow the AI to compare and retrieve text based on its meaning rather than just exact keyword matches.
Retrieval Phase
When the user makes a query, this query is passed to the same AI model to generate a second embedding. The system then compares this query embedding with the embeddings generated during the ingestion phase. It retrieves the five closest embeddings, as these are likely to contain the information most relevant to the question.
Generation Phase
The retrieved information snippets, along with the original query, are then passed to the LLM. With this additional context, the LLM can generate a much more accurate and relevant response to the user query. This process allows the LLM to utilize specific information that was not included in its original training data, significantly enhancing its ability to provide useful answers.
Privacy and Customization
These examples have been made using only LLMs that run locally. This allows for the implementation of AI that is very specific to a user’s needs and places a strong emphasis on privacy. By running the models locally, users can ensure that their data and queries remain confidential, without being sent to external servers. This setup is particularly beneficial for businesses and individuals who handle sensitive information and require robust data privacy.
How Simplificator can help you
AI continues to revolutionize the way we interact with technology, and Retrieval-Augmented Generation is a prime example of its potential. By enhancing large language models with real-time information retrieval, RAG offers a powerful solution to the limitations of traditional keyword-based search systems. In cases where privacy-focused applications are essential, Simplificator can assist in implementing RAG systems tailored to specific user needs. By leveraging RAG technology, Simplificator ensures that your company’s proprietary information is utilized efficiently and securely, enhancing the overall user experience while maintaining strict privacy standards.
Do you want to know more? Get in touch with us and book a meeting right HERE